Jan 2026 – Present
CMU Language Technologies Institute
Researching dynamic Mixture-of-Experts architectures under Chenyan Xiong, developing adaptive strategies that expand model capacity on out-of-distribution data while mitigating reasoning degradation in continual pretraining.
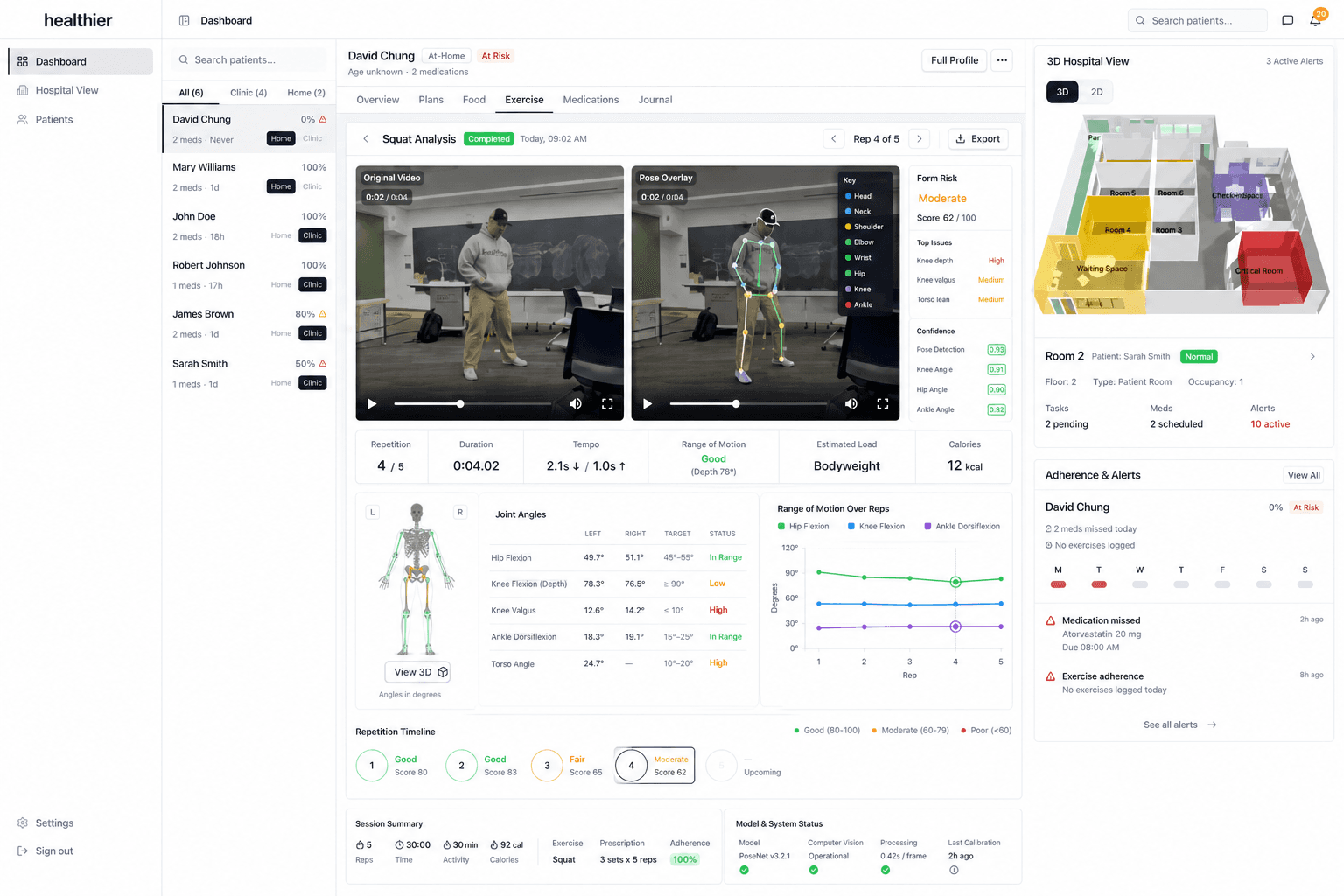
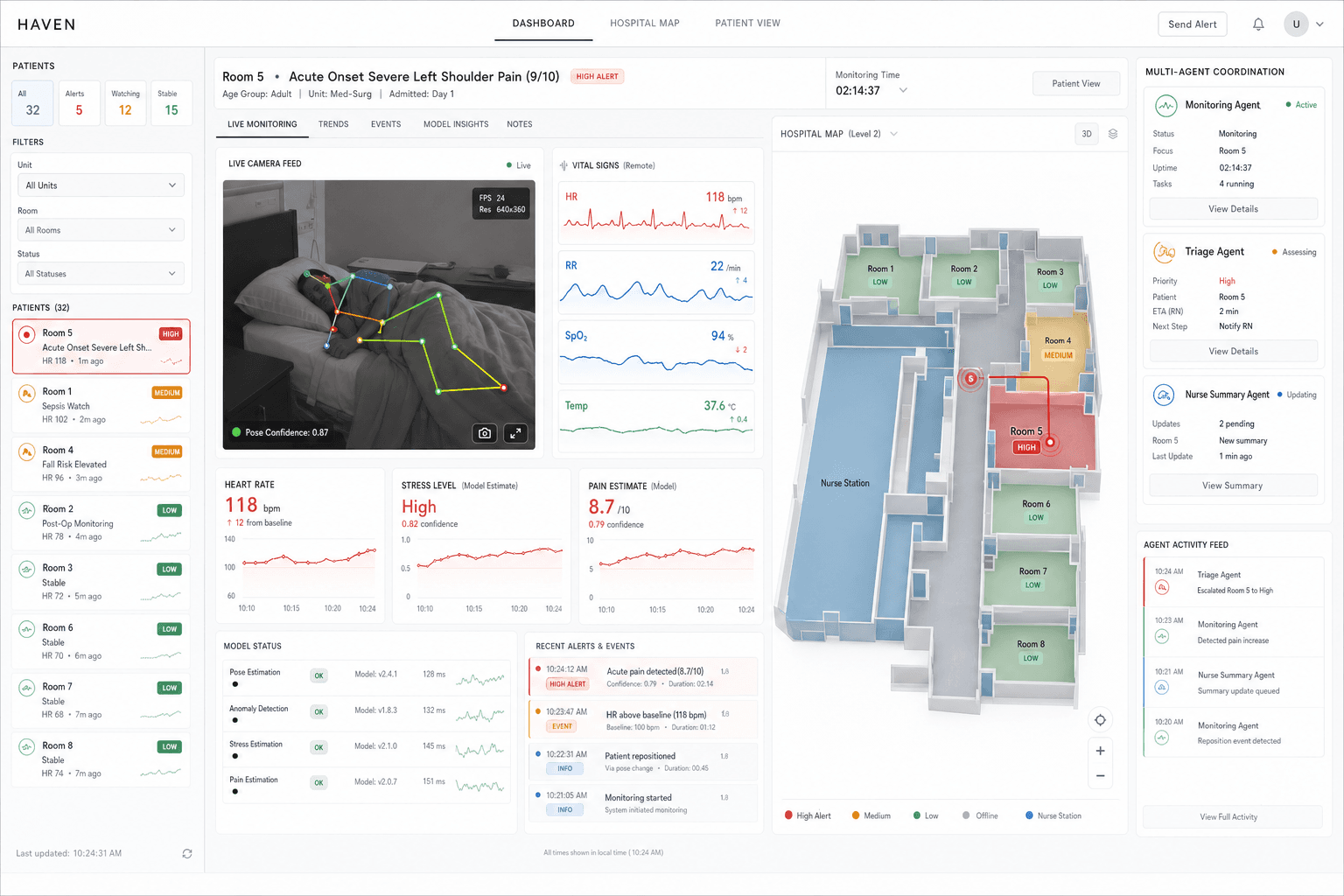
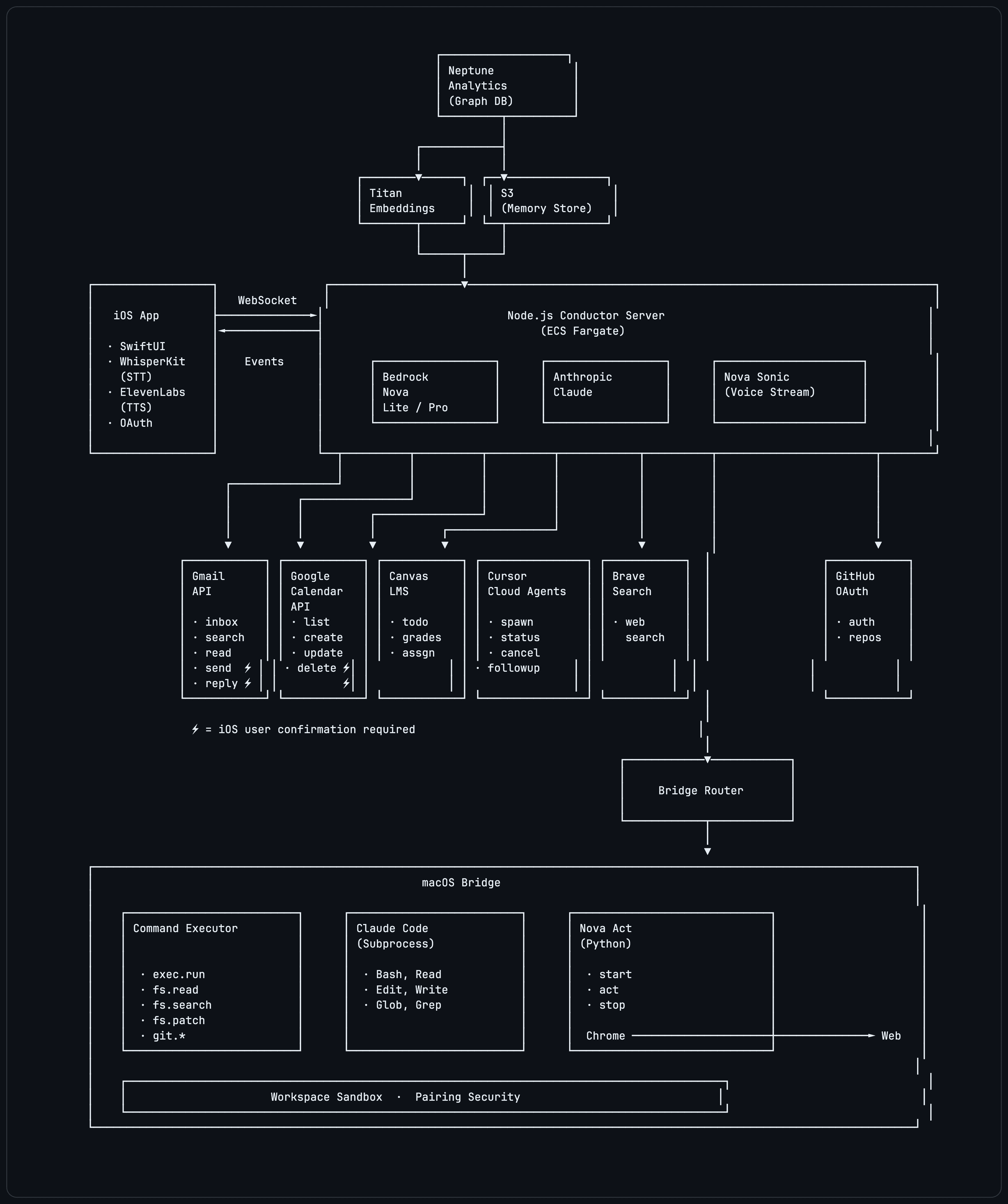
Designing autonomous research agents that propose, execute, and evaluate model-adaptation experiments across tasks and modalities including vision, clinical, and financial time-series data, iteratively committing variants that improve reasoning and task-benchmark performance over dense backbones.