Intuition: use LLaVA as a starting point, experiment with Q-Former for vision modality. When shifting over to MoE, may need to incorporate aspects of MoExtend-Calibration, etc
Goal: add a new modality (e.g. vision) to a base MoE architecture
Status Update:
- 2026-02-11: Read through the LlaVA to MoE-LLaVA lineage; those two papers seem like good initial starts. Currently need to look into compatability with LoRA as well as what Q-Former is.
Focus Papers:
- Q-Former
- FlexOlmo
LlaVA (Visual Instruction Tuning): Language Model + Vision Encoder + Projection Layer
- Pre-training for feature alignment: freeze the vision encoder and language model, train the project layer
- Fine-tuning: keep the vision encoder frozen, fine tune the language model and projection layer
Code: https://github.com/haotian-liu/LLaVA
Paper: https://www.alphaxiv.org/abs/2304.08485
Issues: catastrophic forgetting, large fine-tuning cost
MoExtend: Tuning New Experts for Modality and Task Extension
Note: LLaVA successor
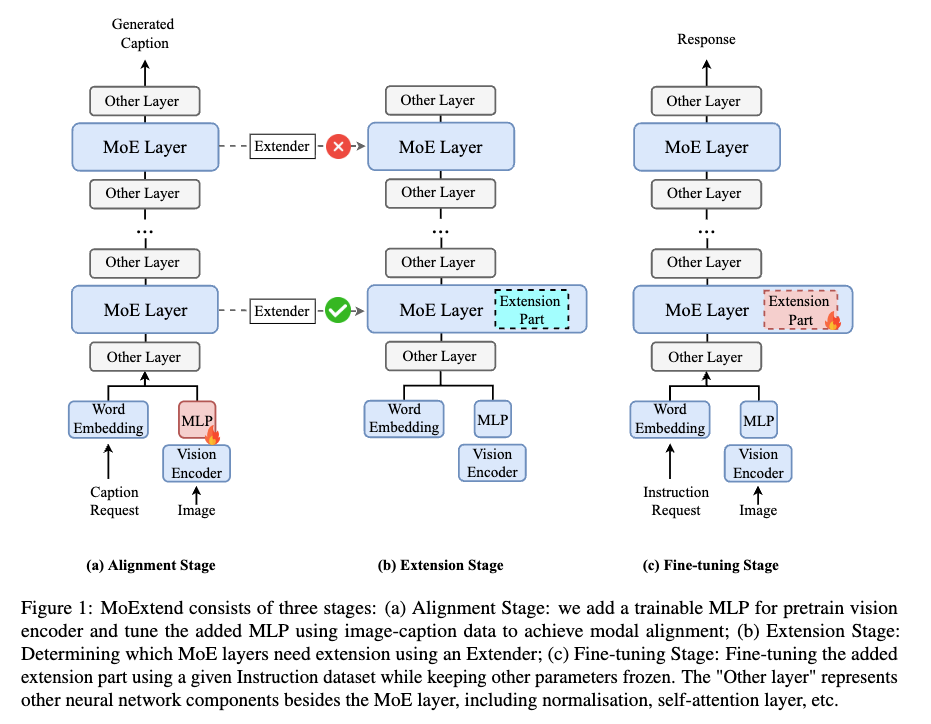
- Alignment: add a trainable MLP for vision encoder, tune using image-caption pairs for modal alignment
- Extension Stage: determine which MoE layers need extension using an Extender
- Fine-tuning stage: fine tuning the added extension given an Instruction dataset while keeping other parameteres frozen
Extension Stage: Extender
- randomly sample 10k instruction data related to the new modality as the validation set, with the remaining data forming the sub-training set. The sub-training set is used to train the extender, and then evaluate the new and old model on the validation set, analyzing which layers are most sensitive to the new modality. The new expert is copied from the expert within the layer that reacted most to the new modality, and the router is extended.
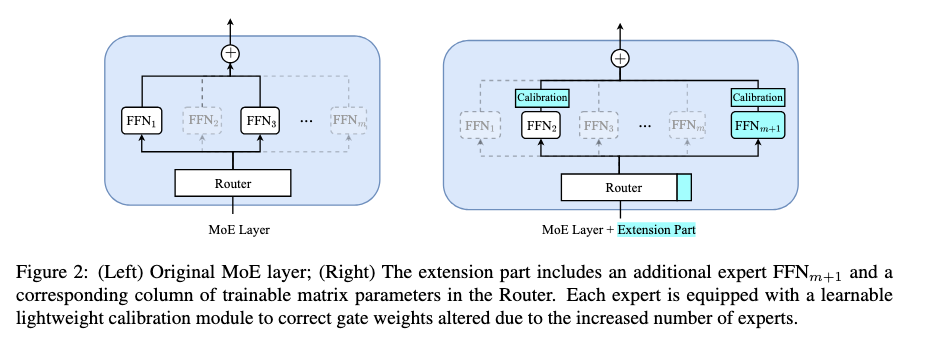 Calibration Module:
Calibration Module:
- Problem: adding new experts intrinsically decreases weightage of the old experts, which causes implicit forgetting; even when not changing old expert weights.
- Solution: Add a calibration module after the router that rescales old expert weights to prevent forgetting. Discover exact methodology in code
Fine-Tuning Stage
- Train calibration modules, new expert, and the new router column
Code: https://github.com/zhongshsh/MoExtend
Paper: https://www.alphaxiv.org/abs/2408.03511?chatId=019c4337-293d-791a-8319-d013adba3b75
MoE-LLaVA: Mixture of Experts for Large Vision-Langauge Models
Note: MoExtend successor
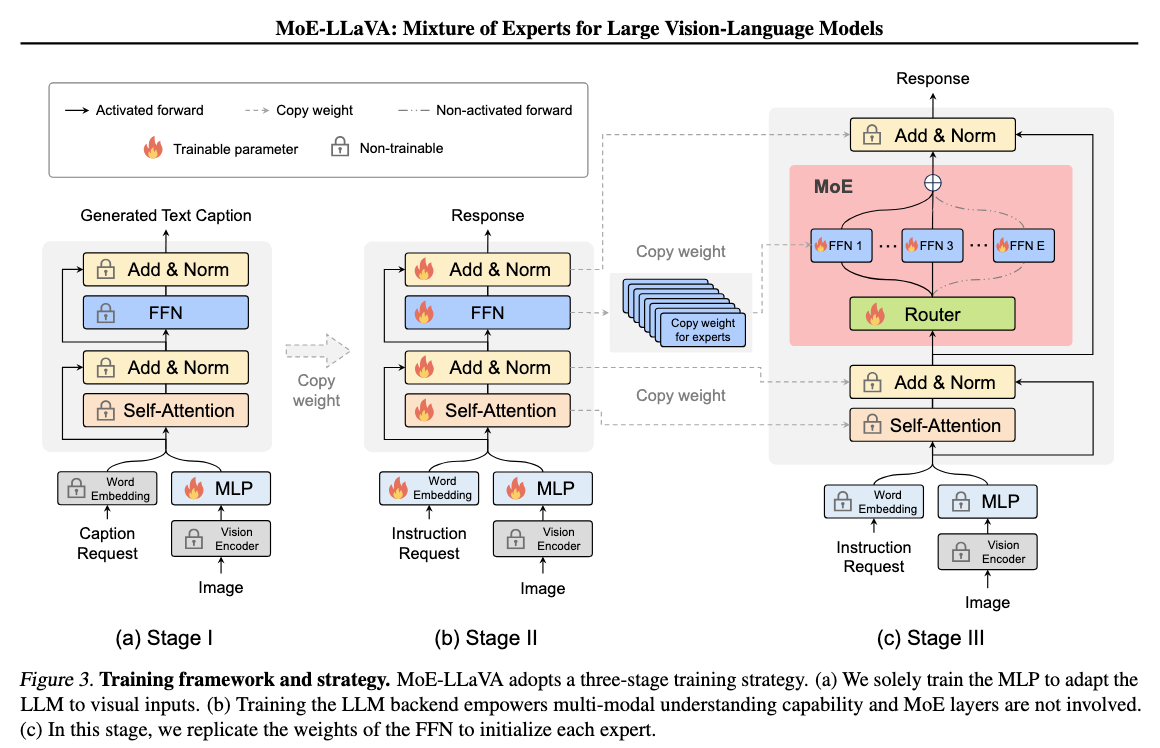
- Train the MLP for feature alignment
- Train all paremeters aside from the Vision Encoder (VE). Adapt the LLM to become an LVLM with multi-modal capabilities through more complex instructions including tasks such as image logical reasoning and text recognition.
- Replicate the FFN as initialization weights for the new experts and train only MoE layers. Each token is processed by the top-k experts selected by the router.
Losses: Load Balancing Loss & Cross Entropy (Auto Regressive)
Ablation Studies:
Code: https://github.com/PKU-YuanGroup/MoE-LLaVA
Paper: https://arxiv.org/abs/2401.15947
Med-MoE
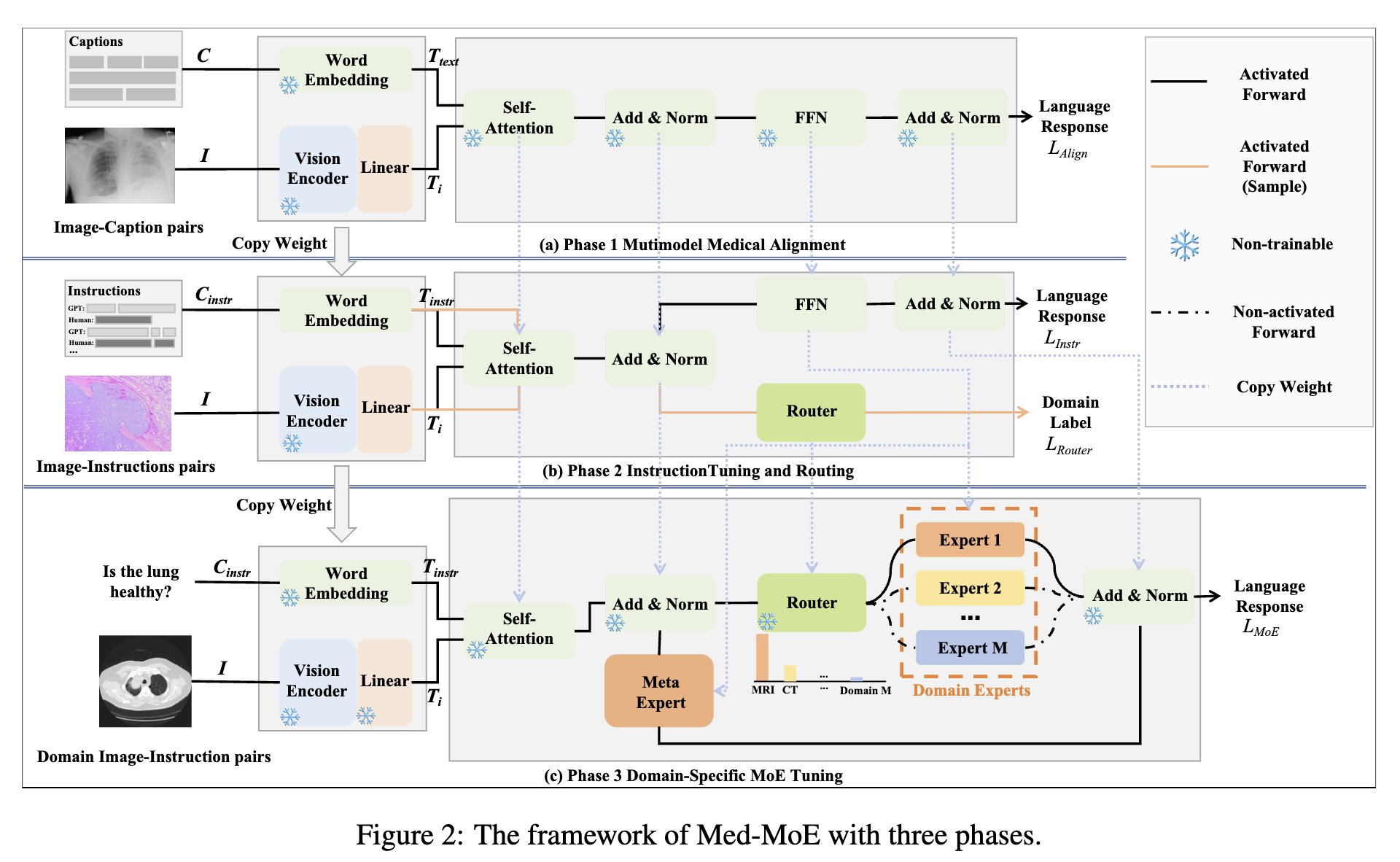
- Multimodal Medical Alignment: train the project layer to align modalities
- Instruction Tuning and Routing: enhance model ability to follow complex medical instructions and train a router for the next phase (Important: this is unique). The router learns modality e.g. CT, MRI, Pathology, X-Ray
- Domain-Specific MoE Tuning: duplicate the FFN as init weights for the new experts, only train MoE domain experts and the meta expert
Code: https://github.com/jiangsongtao/Med-MoE
Paper: https://www.arxiv.org/abs/2404.10237
Blip-2: Bootstrapping Language-Image Pre-training
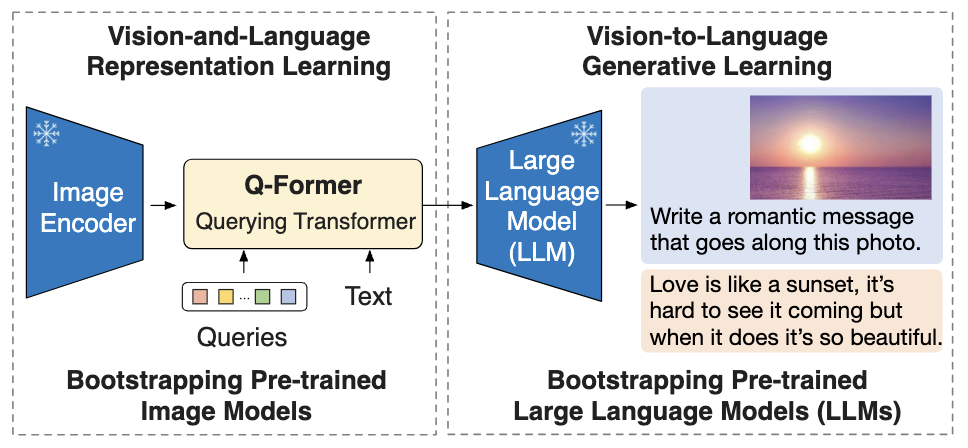
- Representation Learning:
- Generative Learning:
Code: https://github.com/facebookresearch/blip2
Paper: https://arxiv.org/abs/2201.12597
FlexOlmo:
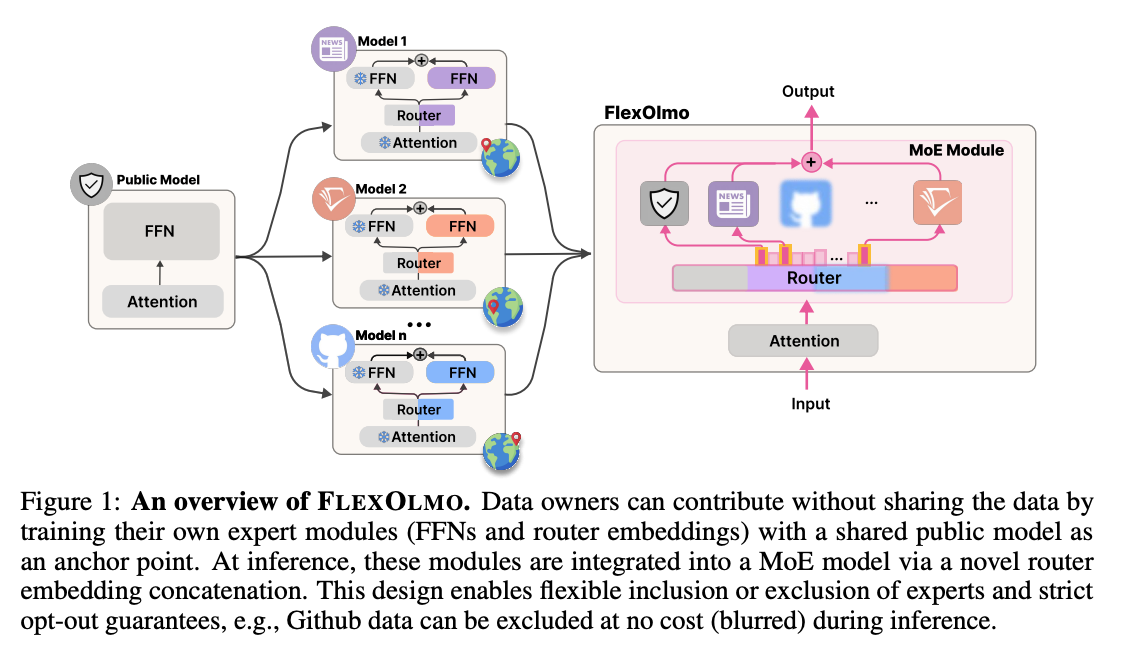 1.
1.
Code: https://github.com/allenai/FlexOlmo Paper: https://allenai.org/papers/flexolmo