Transformer Efficiency Techniques
Flash Attention
- Computes attention in tiles/blocks rather than materializing the full attention matrix
- Uses online softmax to compute attention incrementally, recomputing values during backward pass instead of storing them
- Reduces memory from to while maintaining exact attention (not an approximation)
- Key insight: memory I/O is the bottleneck, not FLOPs—trading compute for memory access is a net win on modern GPUs
KV Cache
- During autoregressive generation, keys and values for previous tokens don't change—cache them instead of recomputing
- Each new token only needs to compute its own and attend to the cached history
- Reduces per-token inference from to attention computation
- Trade-off: memory grows linearly with sequence length , which is why techniques like sliding window attention help for long contexts
Grouped Query Attention (GQA)
- Instead of separate K/V heads per query head (MHA) or one K/V for all queries (MQA), use groups
- Multiple query heads share the same K/V heads within a group (e.g., query heads, KV heads = 4 queries per KV)
- Reduces KV cache size by factor of while retaining most of MHA's expressiveness
- Sweet spot between MQA's efficiency and MHA's quality—used in Llama 2 70B, Mistral, etc.
Rotary Embeddings (RoPE)
- Encodes position by rotating query and key vectors in 2D subspaces based on position index
- Relative position naturally emerges: depends on due to rotation properties
- The rotation matrix applied to position uses angles
- No learned position embeddings—positions are encoded through geometric rotation
- Enables length extrapolation (with modifications like NTK-aware scaling or YaRN) beyond training context
LoRA Experts
- Adapter: Low-Rank Adaptation pair of matrices such that . Lower computational cost
- Routing can use hard routing (top-k, top), soft routing (), condition-based (task ID, language, domain tag), or learned routing
Auxiliary Losses
- Load Balancing Loss: ; penalizes large imbalances in expert utilization
- Router Entropy Loss: ; encourages higher entropy in routing decisions
- Z Loss: keeps logits from exploding
PEFT Strategies
- Full Fine-Tuning (FFT): Updates all backbone parameters, serving as the upper bound for plasticity but often suffering from severe forgetting.
- Standard LoRA: A single low-rank adapter (r = 16) applied to all tasks, representing the standard unified-weight approach.
- Multi-LoRA: Trains independent LoRA adapters for each task, switching them strictly during inference. This serves as a baseline for task isolation but lacks cross-task synergy.
- Vanilla MoE-LoRA: A standard mixture of LoRA experts with uniform layer distribution and Top-K routing, used to isolate the gains derived specifically from our asymmetric allocation and knowledge-preservation mechanisms
On vs Off Policy Learning
- On-policy learning: agent learns from data generated by the same policy being updated; stability & alignment as it learns from data the current policy is generating
- Off-policy learning: agent learns from data generated by a different policy (older versions, a different agent, etc.); sample efficient as they can learn from older data. However, results in value overestimation or value divergence as the learn from stale data. The learned policy drifts away from the states covered at inference time, and errors accumulate rapidly.
Learning Techniques
- PPO: Proximal Policy Optimization — clips the policy update ratio to to prevent destructively large updates while still improving the policy
- DPO: Direct Preference Optimization — bypasses reward modeling by directly optimizing the policy on preference pairs; loss increases log-prob of preferred response relative to rejected:
- GRPO: Group Relative Policy Optimization — samples multiple responses per prompt, ranks them by reward, and optimizes using relative advantages within each group rather than requiring a separate critic model
- RLHF: Reinforcement Learning from Human Feedback — trains a reward model on human preference data, then uses PPO to optimize the policy against that reward while constraining KL divergence from a reference model to prevent reward hacking
Forward vs Reverse KL Divergence
- Forward KL: — penalizes regions where has low probability but has high probability; encourages to cover the entire support of
- Reverse KL: — penalizes regions where has low probability but has high probability; encourages to match where is non-zero
Limitations for MoE
- Expensive and inflexible as it typically needs gradient access to all experts and substantial additional end-to-end training. Usually requires expert models to have similar structure
- Potential Solution: dynamic expert creation and topology
Main Methods for Visual Modalities:
- Adding a visual encoder and projection layer to the LLM
- Cross-modal attention
Notable LLM Architectures & Papers
OLMoE
- Mixture-of-Experts variant of OLMo using top-k routing (typically k=2 or k=8 active experts)
- Each token routed to subset of experts—1B active params from 7B total, for example
- Uses auxiliary load balancing loss to prevent expert collapse (all tokens going to few experts)
- Achieves better performance per FLOP than dense models by decoupling parameters from compute
Paper: OLMoE: Open Mixture-of-Experts Language Models
Montessori Instruct
- Optimizes the teacher LLM to generate synthetic training data tailored to the student's learning preferences
- Uses influence functions to measure how each synthetic data point affects student's reference loss—positive influence = helpful, negative = harmful
- Constructs preference pairs from high/low influence data and trains teacher with DPO to favor generating influential examples
- Key insight: a weaker teacher optimized for the student outperforms a stronger teacher (GPT-4o) using standard synthesis
Paper: Montessori-Instruct: Generate Influential Training Data Tailored for Student Learning
Visual Instruction Tuning
- Attaches a vision encoder (CLIP) to a pre-trained LLM along with a projection layer that connects the vision and language modalities
- Created a multimodal instruction-following dataset through a GPT-4 based data generation pipeline using images with captions and bounding boxes
- Issues: synthetic data quality, visual reasoning depth, computational efficiency (dual-model overhead from CLIP and LLM)
Github Paper: Visual Instruction Tuning
Towards Specialized Generalists: A Multi-Task MoE-LoRA Framework for Domain-Specific LLM Adaptation
- Assymetric layer wise expert allocation: : ensures that lower layers are sparse and preserves fundamental syntax parsing while higher layers caputre high-level task variability
- Soft-merging with adaptive routing; temperature-scaled (learnable-parameter)routing of weights towards a weighted sum output
- Rank aware capacity decoupling — different experts are assigned different ranks based on task complexity
- Dual path architecture: Base experts and Specialist Experts
- Minimal reasoning degradation
- Insights: decoupling knwoledge via gradient isolation (dual path), concentrating expert capcity in the top one-third of transformer blocks was optimal
- Limitation: static expert topology and predefined expert capacity; look into dynamic expert construction
Self-Distillation Enables Continual Learning
- SDFT trains a student model on its own generated outputs (on-policy) using a frozen snapshot of the model (teacher) conditioned on demonstrators that inject knowledge of the task
- Context Distillation: The demonstrations are injected as context into the teacher (in-context learning), and using reverse KL-divergence, the student is encouraged to output responses that match the teacher's distribution (but without the demonstration as context)
Github Paper: Self-Distillation Enables Continual Learning
Visual Instruction Tuning
- Attaches a vision transformer (CLIP ViT-L/14) to a pre-trained LLM along with a projection layer that connects the vision and language modalities
- Trained on a multimodal instruction-following dataset through a GPT-4 based data generation pipeline using images with captions and bounding boxes
Github Paper: Visual Instruction Tuning
MoExtend: Tuning New Experts for Modality and Task Extension
-
- Alignment stage tunes an MLP to bridge the vision encoder and the LLM. Use image-caption pairs to train the MLP.
-
- Extension stage identifies which MoE layers require new experts by evaluating distribution shifts in expert selection when exposed to new modality data. Partially tunes a model, detects which layers have the highest deviation in expert selection patterns (most sensitive to the new modality), and extends those layers with new experts.
-
- Fine tuning stage trains only the newly added experts and their gate parameters along with a calibration module to prevent interference with existing knowledge; calibration modules are used to adjust gate wieghts and ensure model output remains consistent for previously learned tasks.
Paper: MoExtend Tuning New Experts for Modality and Task Extension Github
MoE-LLAVA: Mixture of Experts for Large Vision-Langauge Models
- Vision Encoder, Projection Layer, MoE-Enhanced Language Model
-
- Visual token adaptation. 2. General multi-modal understanding pre-empowerment. 3. MoE Layer Training and Sparsification (transition dense model to moe architecture)
Github Paper: MoE-LLAVA: Mixture of Experts for Large Vision-Langauge Models
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
- Leverages multiple specialized vision encoders based on the specific requirements of each multimodal task: main learning — a single vision encoder is not sufficient for multiple specicialized visual contexts sucha s medical images, charts, or fine-grained text-recognition tasks
- Notable: BiomedCLIP (medical images)
- Further research: Qwen-VL, SPHINX, DINOv2, MoV-Adapter
Github Paper: MoVA: Adapting Mixture of Vision Experts to Multimodal Context
MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models
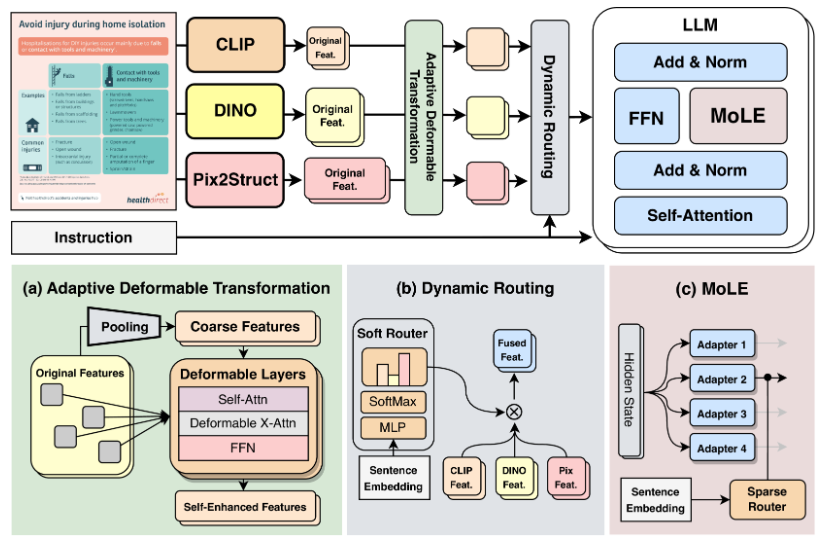
- Mixture of Vision Experts: uses Adaptive Deformable Transformation (MDT) to combine features producted by various vision encoders
- Mixture of Language Experts: to avoid duplication of expesnive FFNs, the paper implements LoRA instead
Github Paper: MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models
Mixture-of-Domain-Adapters: Decoupling and Injecting Domain Knwoeldge to Pre-trained Language Models Memories
- Targets the problem of where knowledge is stored by directly targeting the FFN. Decouples the FFN into an original "old-domain" FFN and a parallel "new-domain" adapter to prevent forgetting. Mixture-of-Adapters (MoA) gate acts as a router, deciding how much knowledge to pull from original FFN and the adapter.
- Two stage training: 1. Domain knowledge injection (training domain adapters while keeping the original LLM/FFN frozen) 2. Task adaptation
- Look into: L2 sampling loss
Mitigating Forgetting in Continuously Pre-training MoE-LLMs by Adding and Chilling Experts
- Add new experts, reduce the learning rate of the old experts
Med-MoE: Mixture of Domain-Specific Experts for Lightweight Medical Vision-Language Models
Miscelanneous Papers
Towards Execution-Grounded Automated AI Research
- autoamted AI research by grounding LLM-generated ideas in high-throughput GPUY execution to verify effectiveness in realistic pre-training and post-training envs
- reinforcement learning from execution rewards successfully increases average idea quality but fails to improve the upper bound of scientific discover — models tend to converge on simple and safe ideas, collapsing in thinking diversity
Github Paper: Towards Execution-Grounded Automated AI Research
Token-Level LLM Collaboration via FusionRoute
- Complementary Routing Mechanism: token level collaboration between LLM that combines expert selection with a corrective mechanism. First, a lightweight router identifies the best expert for the current token based on conversation hidden states. Second, a complementary logit from the router is added to the expert's predictions.
Github - To be released in the next month Paper: Token-Level LLM Collaboration via FusionRoute